
What’s pass-reference-by-value?
I’m not an authority on this - take my explanation with a grain of skepticism and do your own research.
I’ve been working on going over some of the fundamentals of computer science recently since I don’t have a traditional computer science education. Pass-by-value recently came up, and I thought it would be a quick foray to properly learn the difference between pass-by-value and pass-by-reference. Surely something so fundamental must have clear answers, right?
And then it turned into a huge fucking rabbit hole, with lots of dissenting views, and very confusing discussions. Just Google it, check out some of the StackOverflow articles. There’s a lot of content, but it’s not very clear. In the abstract, the concepts are simple. In the context of Python and Ruby, it’s a confusing mess.
So that’s what this post is about - trying to clarify the differences between the two and define what “pass-reference-by-value” actually means.
Quick, naive explanation
The TL;DR version of pass-by-value vs pass-by-reference is simple - pass by value means the value of a function parameter gets copied into the body of a function, but it’s not the same object in memory as the original parameter. You can’t mutate or change whatever you passed into the function, because your function doesn’t actually know about the original “thing” - it only has a copy of the value of the “thing.”
Pass-by-reference is the opposite. When you invoke a function with a parameter, the function body is referring to the same object in memory as the original. Any mutations of the object inside the function body will be persisted outside of the function body.
We can see an example of pass-by-value with a little Ruby:
my_string = 'foo'
puts "my_string is '#{my_string}'" # my_string is 'foo'
def mutate(some_string)
some_string = 'not foo'
puts "string inside function is '#{some_string}'"
end
mutate(my_string) # string inside function is 'not foo'
puts "my_string is still '#{my_string}'" # my_string is still 'foo'
You can do the same thing in Python, Java, or any other pass-by-value language
and get the same result. And it makes perfect sense - inside the function,
some_string simply has the value of foo, so if we assign it to something
else it doesn’t affect my_string elsewhere in the function.
A contradicting example
Let’s do one more simple example in Ruby, to build confidence in our newfound understanding.
my_string = 'foo'
puts "my_string is '#{my_string}'" # my_string is 'foo'
def mutate(some_string)
some_string.upcase!
puts "string inside function is '#{some_string}'"
end
mutate(my_string) # string inside function is 'FOO'
puts "my_string is now '#{my_string}'" # my_string is now 'FOO'
Confused? Yeah, me too. This confusion is what spurred my research. We know Ruby uses pass-by-value, we just empirically demonstrated that as fact - so how is it possible that we could mutate an object inside of a function and have that change persist outside of the function?
For anyone who uses Ruby or Python, they might argue that it behaves like pass-by-reference. Other people would explain the behavior by saying Ruby and Python are “pass-reference-by-value” or “pass-object-by-value” but what exactly does that mean?
More layers to the cake
It turns out that there are really two layers to this behavior, and everything makes a lot more sense once you are familiar with them.
A language can support pass-by-reference or pass-by-value semantics, or both. For example, C# supports both On top of that, the type of parameters you pass into a function can be a value type or a reference type, regardless of whether pass-by-value or pass-by-reference semantics are used. This is what makes classifying languages so confusing - a language that uses pass-by-value semantics and reference types appears to behave like pass-by-reference.
Let’s go back to our Ruby examples. Ruby is always pass-by-value. However we
saw earlier that it behaved like a pass-by-reference language. That’s because
the value of the my_string parameter is a reference to an object in
memory. The value is still being copied when the function is invoked (hence
pass-by-value), but the value is a reference to the same object in memory.
Let’s do another quick example in Ruby to demonstrate this:
my_string = 'foo'
puts "my_string is '#{my_string}'" # my_string is 'foo'
puts my_string.object_id # 60
def mutate(some_string)
puts some_string.object_id # 60
some_string.upcase!
# object_id will still be 60 - still referring to the same object in memory
puts some_string.object_id # 60
puts "string inside function is '#{some_string}'" # string inside function is 'FOO'
# assigning a value to `some_string` creates a new object in memory, and the value
# is updated to reference that new object in memory. it did not change the original
# object in memory. because of this, the ID will be different
some_string = 'not foo'
puts some_string.object_id # 80
end
mutate(my_string)
puts "my_string is now '#{my_string}'" # my_string is now 'FOO'
For those who need visual help like me, here’s a series of diagrams explaining the same concept. In each digram, the code will be on the left and a model of the objects in memory will be on the right.
When we first initialize my_string with the value 'foo', a new object is
created in memory that holds the string foo.

When we invoke the mutate method and pass in my_string, a copy of
my_string is made. That copy has the variable name some_string, and the
value of the variable is the reference to the object in memory (not the
string foo). It’s a new variable inside of the function scope, but it refers
to the same object in memory.

If we mutate the object inside the function body, it affects the object both inside and outside of the function scope.
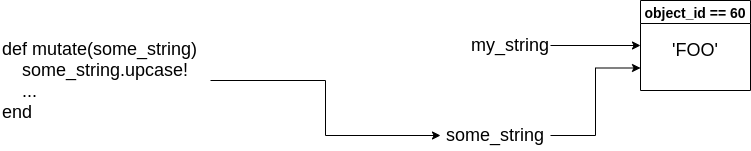
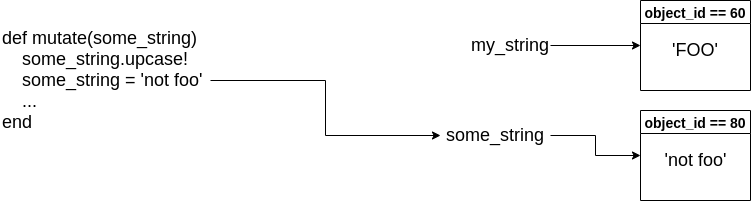
Now here’s where the difference between pass-reference-by-value and true
pass-by-reference is made clear. If Ruby were pass-by-reference, we could
update my_string to refer to a new object in memory. But we can’t - we never
actually had my_string within the scope of our function, just a copy of that
variable that refers to the same object in memory. If we try to assign
some_string to a new object, it has no effect on my_string outside of the
function body. It just creates a new object in memory.
Compared to languages with pointers
Rust, Golang, C, and C++ all support pointers. Some people will say that this means you can write functions with pass-by-value or pass-by-reference semantics. Don’t believe their lies - strictly speaking, these languages are also pass-by-value.
In Ruby and Python, every variable is a reference to an object in memory. In Rust/Golang/C++, both references and pointers are supported. However the differences between pointers and references is subtle, and don’t affect the examples we used in this post. The ELI5 version is that references are like “implicit pointers” and don’t require extra syntax to de-reference them. We could implement the same exercises above in any of these languages, using references or pointers, and the behavior would be the same.
So the only real difference is that these languages require us to be explicit about pointers/references, whereas Ruby and Python use references implicitly.
Conclusion
In short, pass-reference-by-value is just pass-by-value with implicit references. Unless you’re using C#, Perl, or some exotic language, you’re more than likely using pass-by-value, either with explicit pointers/references (Golang, Rust, C++) or implicit references (Python, Ruby).
I hope this helps demystify the nature of pass-reference-by-value for you and spares you the StackOverflow rabbit hole. Here are some links for content I reviewed to learn about this, in case you want to do your own research:
- Is Ruby pass by reference or pass by value?
- my post is like the ELI5 version of this post. What I didn’t understand was that assignment was the key difference in behavior
- StackOverflow - Is Ruby pass by reference or by value?
- This answer in particular made it more clear to me
- C# vs Python argument passing
- Value type and reference type
- Variable References and Mutability in Ruby
Leave a Comment