
Download All Files From A Site With wget
I recently got a membership to a site hosting a boatload of private label rights (PLR) material (IDPLR.com). 99% of PLR items are scams, garbage, or are outdated, but if you have the time or tools to dig through it you can find some gems. (Just so we're clear, I'm not running any scams, I was just looking for some content for another project). Anyway, I got access to the site that had thousands of zip files but obviously didn't want to download them one by one. Administrator wouldn't give me any way to download the files in bulk either, so I was left with no choice but to automate...
This is one of those projects that can be done a dozen different ways. There's probably a real slick way to do this with one line of code, but this method worked for me.
Step 1 - Identify your targets
This was the most challenging part for me, until I got lucky and found a blog post on how to grab EVERY link on a site using wget. I can't take any credit for this script, so I'll just share my slightly modified version:
MYSITE='http://www.idplr.com'
wget -nv -r --spider $MYSITE 2>&1 | egrep ' URL:' | awk '{print $3}' | sed "s@URL:${MYSITE}@@g" >> links.txt
This will create a file, links.txt, that contains EVERY link found on the site you specified for your "MYSITE" variable. Very powerful one-liner for sure. Keep in mind it may take a very long time for this command to complete (about an hour in my case).
We don't want to download every file on the site, so we need to whittle down our list. In my case, all of the files I wanted to download were conveniently in a directory labeled "downloads" (albeit in several different child directories) so I used the following command to create a new file (downloads.txt) that contained only the links to the "downloads" directory.
less links.txt | grep downloads/ >> downloads.txt
The downloads.txt file looks like this:
...
/members/protect/new-rewrite?f=11&url=/downloads/ebooks/gold/AffiliateFitnessCraze_rr.7594.zip&host=www.idplr.com&ssl=off
/members/protect/new-rewrite?f=11&url=/downloads/ebooks/gold/AzonHairLossEssentials_rr.7592.zip&host=www.idplr.com&ssl=off
/members/protect/new-rewrite?f=11&url=/downloads/ebooks/gold/AzonHalloweenEssential_rr.7591.zip&host=www.idplr.com&ssl=off
...
You'll see that the site scraper pulled the URL of the redirect that is protecting the members-only files. We don't want the strings appended and pre-pended to the path, we just want the /downloads.../filename.zip. So let's use 'awk' to strip out all of that garbage and give us just the path to the files.
awk -F'&url=' '{print $2}' downloads.txt | awk -F'&host' '{print $1}' >> cleanLinks.txt
Let's break down what the awk command does in this case. The -F flag allows you to set a delimiter, in this case '&url=', to break up the string. Since that string only appears once per line, the line is broken into two strings - all of the characters leading up to the delimiter, and all of the characters after the delimiter, not including the delimiter. Then we use '{print $2}' to print that second chunk of the string. So at this point we've stripped the string down to:
"/downloads/dirname/dirname/filename.zip.&host=www.idplr.com&ssl=off."
Well we don't any of the garbage after the file name, so we'll pipe the output from the first awk command into a second awk command. Again, we specify a delimiter (-F '&host') to split the string into two pieces, then print only the first half of the string ('{print $1}' above). The output now will be "/downloads/dirname/dirname/filename.zip" - perfect! Finally, by using the ">>" redirection, the output from these commands will be written to a new file, cleanLinks.txt. Target acquired.
Step 2 - Scripting the Download with Login Parameters
Just for a test, I tried to run 'wget' against one of my targets, and ended up with an HTML file. That's because the site was redirecting me to the log in screen, and wget followed the redirect and downloaded that page instead. Same thing would happen in your browser; if you try to browse to that link without authenticating first, you get re-routed to the log in screen. No problem - we just need to figure out how the redirect and log in screens are working. I'm using the built-in console in Chrome for this, but there are many tools out there for looking at HTTP requests and responses. If you are following along word for word, pull up Chrome, punch in the link for a protected file and let the browser get redirected to the log in screen. Then press F12, or right click anywhere on the site and choose "Inspect Element." The console should pop up on the bottom of the browser window. Click the Network tab, and the record button (gray circle at the bottom, will turn red when clicked). For example:
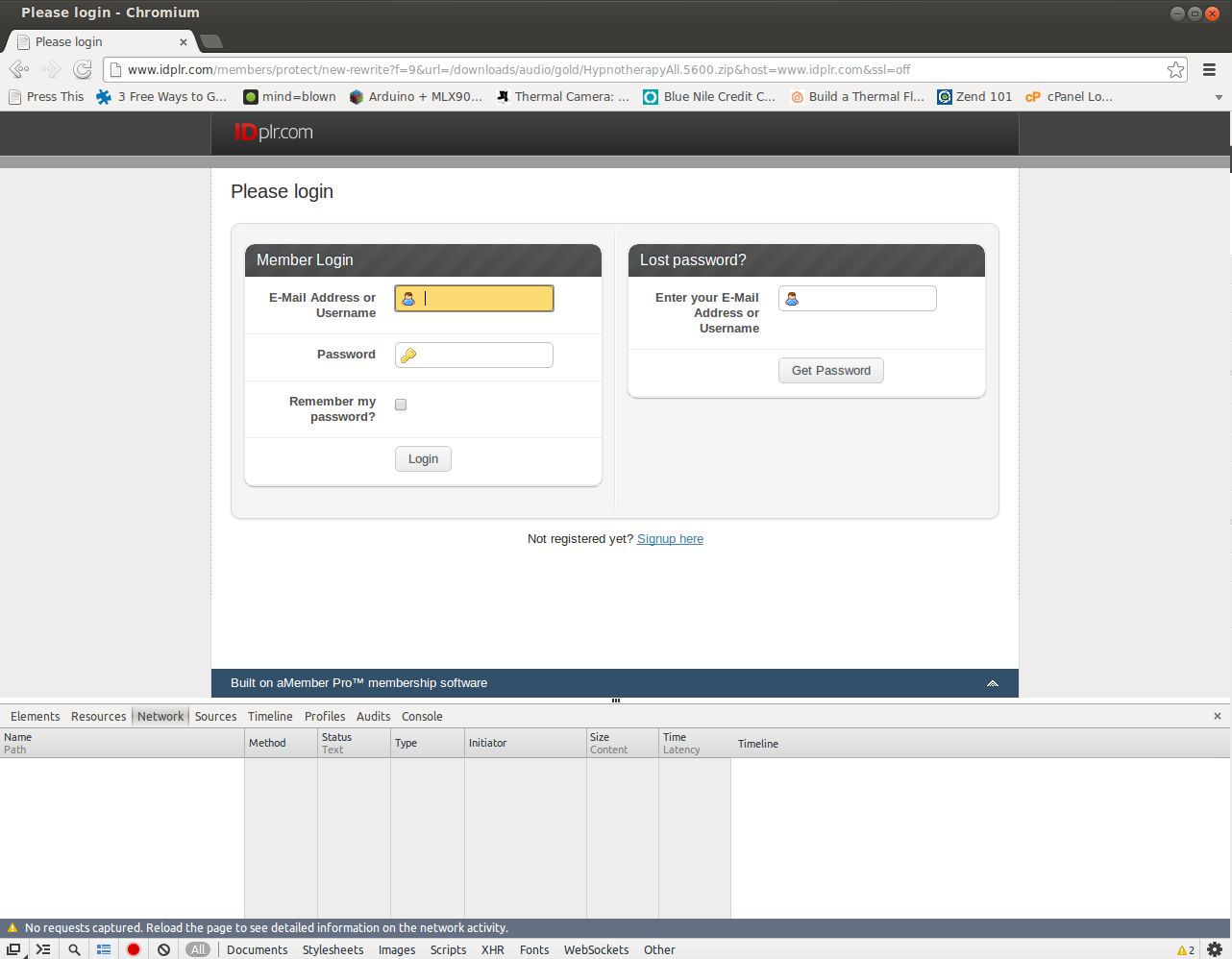
The console will now record all HTTP requests and their responses, even as you traverse to different pages (if you didn't click the "record" button, it only shows you current requests). Now, log in using your credentials and watch all of the requests and responses fly past. The file should also started downloading - if not, go back, because the next part will be worthless if you didn't authenticate properly and get to the file you expected to. Find the request on the left of the console labelled 'login' (this could obviously be different if you're downloading from a different site) and look at the request headers. Under Form Data, click "view source".
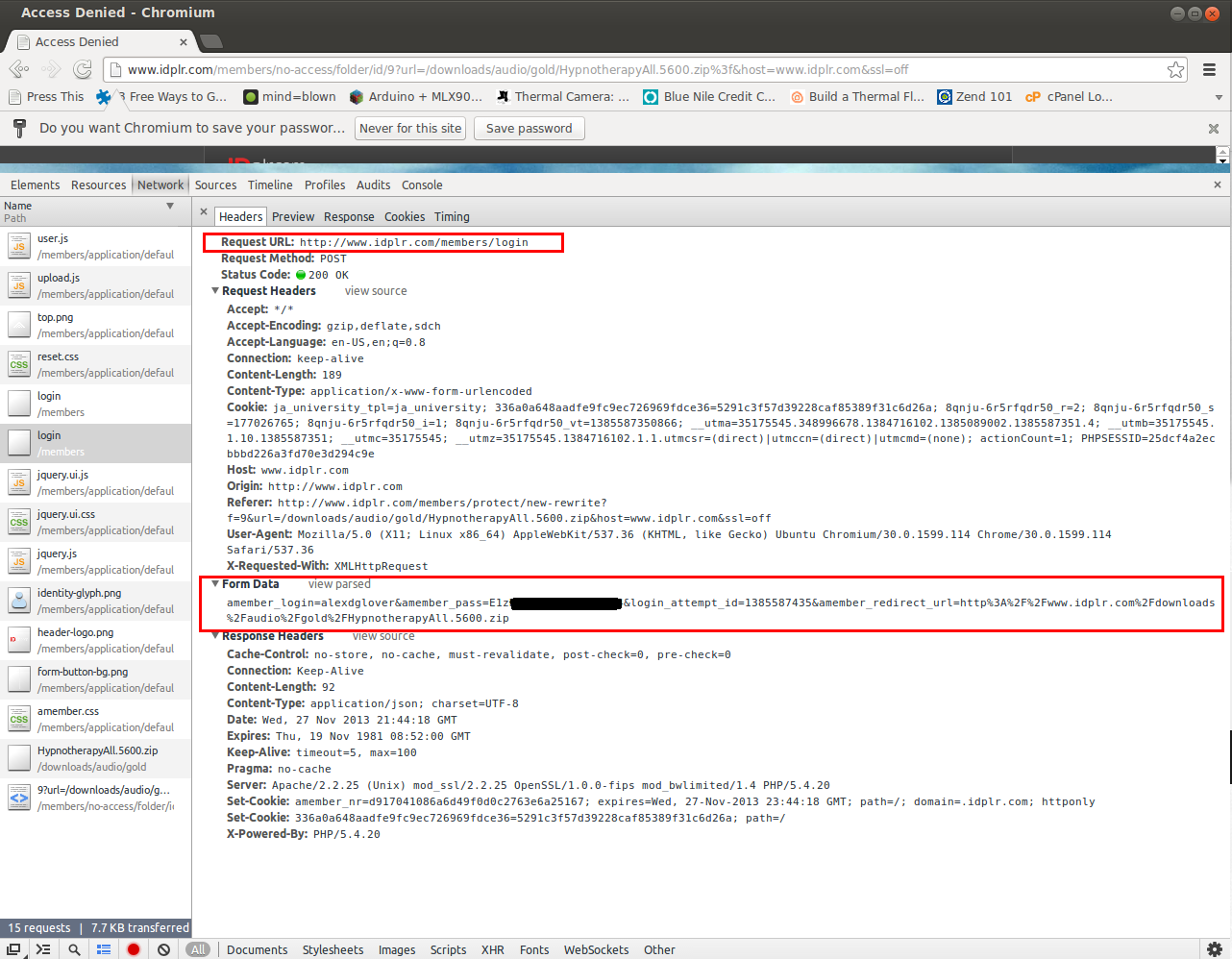
The key information is highlighted in the red boxes. The request URL is the URL we sent our HTTP request to. The form data is the username and password we entered, plus some hidden and generated fields that were in the form (check the w3schools page if you need more information on forms in HTML). Now, to verify it works, try this wget command:
wget http://www.idplr.com/members/login -O <insert file name here> \
--post-data="amember_login=<your_username>&amember_pass=<your_password>&login_attempt_id=1384717099&amember_redirect_url=<link_to_the_file>
So for example, if I wanted to download "SlipstreamMarketing.2196.zip", my command would like this:
wget http://www.idplr.com/members/login -O SlipstreamMarketing.2196.zip \
--post-data="amember_login=alexdglover&amember_pass=E1zxxxxxxxxxxx&login_attempt_id=1384717099&amember_redirect_url=http://www.idplr.com/downloads/ebooks/free/SlipstreamMarketing.2196.zip"
Now, if you've gotten this far and everything is working, the rest is cake.
Step 3 - Adding the Loop
At this point, we have a text file that has a path to each file we want to download on each line (cleanLinks.txt), and a way to authenticate and download that file in one command (see Step 2). We just need to write a bash script that executes that command for each line in the file. Create a file with your favorite text editor, and enter the following code:
# execute the following code block for each line in the text file
while read line; do
# Create a new variable, filename, to hold the actual filename instead of the full path (name.zip, instead of /path/to/file/name.zip)
filename=$(basename $line)
# Echo the filename out to the terminal for debugging purposes
echo $filename
# Echo out the path that wget will attempt to use to download a file
echo "Attempting to download file at http://www.idplr.com$line"
# Execute our wget one-liner, but this time with the filename and path to the file as variables ($filename and $line)
wget http://www.idplr.com/members/login -O $filename --post-data="amember_login=alexdglover&amember_pass=E1zxxxxxxxxxx4&login_attempt_id=1384717099&amember_redirect_url=http://www.idplr.com$line"
# End of the while loop, and setting the text file (cleanLinks.txt) that the loop should read
done < cleanLinks.txt
Don't forget to save your new script file, and execute "chmod u+x scriptname.sh" to make it executable. Be advised - the script will download files to the whatever directory you execute it from (if the script is in /home/alex/script.sh, but my current working directory is /home/alex/downloads/ and I execute the script, all of the downloads will end up in /home/alex/downloads/). Once you're in the right directory, just execute the script, sit back, and relax.
Leave a Comment